InfoGCN: Representation Learning for Human Skeleton-based Action Recognition
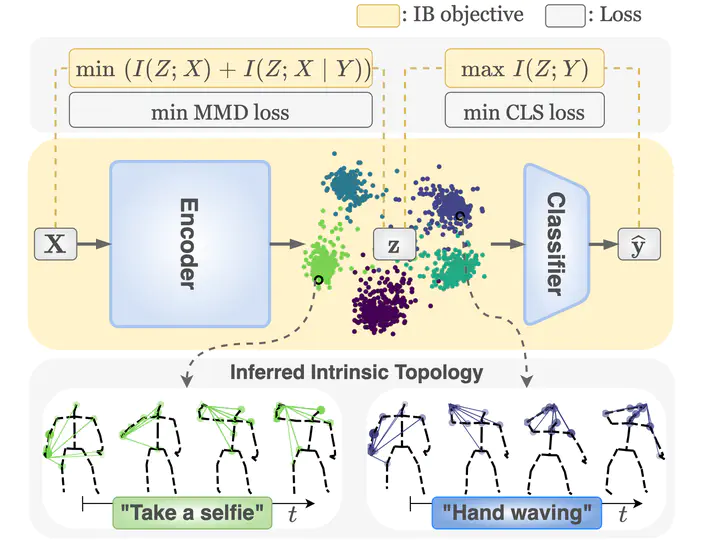 Image credit: Unsplash
Image credit: Unsplash
Abstract
Human skeleton-based action recognition offers a valuable means to understand the intricacies of human behavior because it can handle the complex relationships between physical constraints and intention. Although several studies have focused on encoding a skeleton, less attention has been paid to incorporating this information into the latent representations of human action. This work proposes a learning framework for action recognition, InfoGCN, combining a novel learning objective and encoding method. First, we design an information bottleneck-based learning objective to guide the model to learn an informative but compact latent representation. To provide discriminative information for classifying action, we introduce attention-based graph convolution that captures the context-dependent intrinsic topology of human actions. In addition, we present a multi-modal representation of the skeleton using the relative position of joints, designed to provide complementary spatial information for joints. InfoGCN surpasses the known state-of-the-art on multiple skeleton-based action recognition benchmarks with the accuracy of 93.0% on NTU RGB+D 60 cross-subject split, 89.8% on NTU RGB+D 120 cross-subject split, and 97.0% on NW-UCLA.
In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Seunggeun Chi
Ph.D. student | Research Assistant
My research interests include distributed robotics, mobile computing and programmable matter.